
Table of Content
- Introduction
- About Sentiment Analysis and It’s Working
- Import Necessary Libraries
- Importing Dataset
- Data Preprocessing / Text Cleaning
- Plotting WordCloud
- Visualizing Cleaned dataset
- Building LSTM model
- Conclusion
Introduction
Stock market is one of the most sensitive markets, where entire market depends upon the sentiment of the peoples and they can change the trend of the market. There are also others factors which decide the trend of market and one of them are everyday news.
Have you ever wondered what would be the impact of everyday news on stock market trend?
Volatile nature of stock market gives the equal opportunity to earn money to all and also have a risk to loss it as well. But if we can predict the trend or situation of market we can make profit or minimize the losses.
And here A.I. plays an important role to predict the stock market trend or movement of particular stock whether they will go up or fall down using sentiment analysis.
About Sentiment Analysis and It’s Working
Sentiment analysis is a process of analyzing the sentiment of peoples from various sources where they can freely express their feelings and opinion like social media, stock market related blogs, etc. Such sources influence the other peoples to make decision accordingly.
It uses Natural Language Processing (NLP) to divide the sentiment into three categories like positive, negative and neutral. If the sentiment is positive then stock price may increases, if it is negative price may decrease and if it is neutral it maybe neither increase nor decrease.
If you want to know more about NLP and its process, you can read my previous article on it from here.
In this article we are going to do sentiment analysis using LSTM model.
Import Necessary Libraries
# Importing Libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import plotly.express as px
# Import packages for TensorFlow deployment import tensorflow as tf from tensorflow.keras.models import Model,Sequential from tensorflow.keras.preprocessing.text import one_hot,Tokenizer from tensorflow.keras.layers import Dense, Flatten, Embedding, Input, LSTM, Conv1D, MaxPool1D, Bidirectional, Dropout from tensorflow.keras.utils import to_categorical from tensorflow.keras.preprocessing.sequence import pad_sequences
# Import NLP And Gensim # Gensim is a open source lib which we have used for unsupervised topic modeling and nlp from wordcloud import WordCloud, STOPWORDS import nltk import re from nltk.stem import PorterStemmer, WordNetLemmatizer from nltk.corpus import stopwords from nltk.tokenize import word_tokenize, sent_tokenize import gensim from gensim.utils import simple_preprocess from gensim.parsing.preprocessing import STOPWORDS
Importing Dataset
We have a stock news data taken from various twitters handles post regarding news of stock trends. You can download the file in CSV format by clicking on this link, download data. Save it in your working directory to access using below code.
stock = pd.read_csv("stock_data.csv")
# Dispaly all columns
pd.set_option('display.max_columns', None)
stock
Text Sentiment
0 Kickers on my watchlist XIDE TIT SOQ PNK CPW B... 1
1 user: AAP MOVIE. 55% return for the FEA/GEED i... 1
2 user I'd be afraid to short AMZN - they are lo... 1
3 MNTA Over 12.00 1
4 OI Over 21.37 1
... ...
5786 Industry body CII said #discoms are likely to ... -1
5787 #Gold prices slip below Rs 46,000 as #investor... -1
5788 Workers at Bajaj Auto have agreed to a 10% wag... 1
5789 #Sharemarket LIVE: Sensex off day’s high, up 6... 1
5790 #Sensex, #Nifty climb off day's highs, still u... 1
[5791 rows x 2 columns]
stock.info()
RangeIndex: 5791 entries, 0 to 5790
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Text 5791 non-null object
1 Sentiment 5791 non-null int64
dtypes: int64(1), object(1)
memory usage: 90.6+ KB
stock["Sentiment"].value_counts()
1 3685
-1 2106
Name: Sentiment, dtype: int64
As we can see we have value of 1 which indicate positive sentiment and -1 which indicates negative sentiment but for simplicity we can replace -1 with 0 so that our model will predict well.
stock["Sentiment"] = stock["Sentiment"].replace(-1,0)
Data Preprocessing / Text Cleaning
As the data is taken from twitter we have to remove punctuations from text like hashtag handles and other punctuation marks. Also we have to remove stopwords which don’t play any role in predicting the sentiment of text.
# Removing Punctuation From Text import string string.punctuation
def remove_punct(message):
Test_punc_removed = [ char for char in message if char not in string.punctuation ]
Test_join = ''.join(Test_punc_removed)
return Test_join
stock['Text Without Punct'] = stock['Text'].apply(remove_punct)
stock
Text Sentiment Text Without Punct
0 Kickers on my watchlist XIDE TIT SOQ PNK CPW B... 1 Kickers on my watchlist XIDE TIT SOQ PNK CPW B...
1 user: AAP MOVIE. 55% return for the FEA/GEED i... 1 user AAP MOVIE 55 return for the FEAGEED indic...
2 user I'd be afraid to short AMZN - they are lo... 1 user Id be afraid to short AMZN they are look...
3 MNTA Over 12.00 1 MNTA Over 1200
4 OI Over 21.37 1 OI Over 2137
... ... ...
5786 Industry body CII said #discoms are likely to ... 0 Industry body CII said discoms are likely to s...
5787 #Gold prices slip below Rs 46,000 as #investor... 0 Gold prices slip below Rs 46000 as investors b...
5788 Workers at Bajaj Auto have agreed to a 10% wag... 1 Workers at Bajaj Auto have agreed to a 10 wage...
5789 #Sharemarket LIVE: Sensex off day’s high, up 6... 1 Sharemarket LIVE Sensex off day’s high up 600 ...
5790 #Sensex, #Nifty climb off day's highs, still u... 1 Sensex Nifty climb off days highs still up 2 K...
[5791 rows x 3 columns]
# Removing Stopwords nltk.download('stopwords') stop_words = stopwords.words('english') stop_words.extend(['from', 'subject', 're', 'edu', 'use','will','aap','co','day','user','stock','today','week','year']) def preprocess(text): result = [] for token in gensim.utils.simple_preprocess(text): if len(token) >= 3 and token not in stop_words: result.append(token) return result stock['Text Without Punc & Stopwords'] = stock['Text Without Punct'].apply(preprocess) stock Text Sentiment Text Without Punct Text Without Punc & Stopwords 0 Kickers on my watchlist XIDE TIT SOQ PNK CPW B... 1 Kickers on my watchlist XIDE TIT SOQ PNK CPW B... [kickers, watchlist, xide, tit, soq, pnk, cpw,... 1 user: AAP MOVIE. 55% return for the FEA/GEED i... 1 user AAP MOVIE 55 return for the FEAGEED indic... [movie, return, feageed, indicator, trades, aw... 2 user I'd be afraid to short AMZN - they are lo... 1 user Id be afraid to short AMZN they are look... [afraid, short, amzn, looking, like, nearmonop... 3 MNTA Over 12.00 1 MNTA Over 1200 [mnta] 4 OI Over 21.37 1 OI Over 2137 [] ... ... ... 5786 Industry body CII said #discoms are likely to ... 0 Industry body CII said discoms are likely to s... [industry, body, cii, said, discoms, likely, s... 5787 #Gold prices slip below Rs 46,000 as #investor... 0 Gold prices slip below Rs 46000 as investors b... [gold, prices, slip, investors, book, profits,... 5788 Workers at Bajaj Auto have agreed to a 10% wag... 1 Workers at Bajaj Auto have agreed to a 10 wage... [workers, bajaj, auto, agreed, wage, cut, peri... 5789 #Sharemarket LIVE: Sensex off day’s high, up 6... 1 Sharemarket LIVE Sensex off day’s high up 600 ... [sharemarket, live, sensex, high, points, nift... 5790 #Sensex, #Nifty climb off day's highs, still u... 1 Sensex Nifty climb off days highs still up 2 K... [sensex, nifty, climb, days, highs, still, key... [5791 rows x 4 columns]
Plotting WordCloud
Wordcloud is a visualization technique used for text data representation where size of the words shows its importance or frequency of occurrence of that word.
# join the words into a string stock['Text Without Punc & Stopwords Joined'] = stock['Text Without Punc & Stopwords'].apply(lambda x: " ".join(x)) stock Text Sentiment Text Without Punct Text Without Punc & Stopwords Text Without Punc & Stopwords Joined 0 Kickers on my watchlist XIDE TIT SOQ PNK CPW B... 1 Kickers on my watchlist XIDE TIT SOQ PNK CPW B... [kickers, watchlist, xide, tit, soq, pnk, cpw,... kickers watchlist xide tit soq pnk cpw bpz tra... 1 user: AAP MOVIE. 55% return for the FEA/GEED i... 1 user AAP MOVIE 55 return for the FEAGEED indic... [movie, return, feageed, indicator, trades, aw... movie return feageed indicator trades awesome 2 user I'd be afraid to short AMZN - they are lo... 1 user Id be afraid to short AMZN they are look... [afraid, short, amzn, looking, like, nearmonop... afraid short amzn looking like nearmonopoly eb... 3 MNTA Over 12.00 1 MNTA Over 1200 [mnta] mnta 4 OI Over 21.37 1 OI Over 2137 [] ... ... ... ... 5786 Industry body CII said #discoms are likely to ... 0 Industry body CII said discoms are likely to s... [industry, body, cii, said, discoms, likely, s... industry body cii said discoms likely suffer n... 5787 #Gold prices slip below Rs 46,000 as #investor... 0 Gold prices slip below Rs 46000 as investors b... [gold, prices, slip, investors, book, profits,... gold prices slip investors book profits amid c... 5788 Workers at Bajaj Auto have agreed to a 10% wag... 1 Workers at Bajaj Auto have agreed to a 10 wage... [workers, bajaj, auto, agreed, wage, cut, peri... workers bajaj auto agreed wage cut period apri... 5789 #Sharemarket LIVE: Sensex off day’s high, up 6... 1 Sharemarket LIVE Sensex off day’s high up 600 ... [sharemarket, live, sensex, high, points, nift... sharemarket live sensex high points nifty test... 5790 #Sensex, #Nifty climb off day's highs, still u... 1 Sensex Nifty climb off days highs still up 2 K... [sensex, nifty, climb, days, highs, still, key... sensex nifty climb days highs still key factor... [5791 rows x 5 columns]
# Most common words used in Positive Sentiment plt.figure(figsize = (20,20)) wc = WordCloud(max_words = 1000 , width = 1600 , height = 800).generate(" ".join(stock[stock['Sentiment'] == 1]['Text Without Punc & Stopwords Joined'])) plt.imshow(wc, interpolation = 'bilinear');
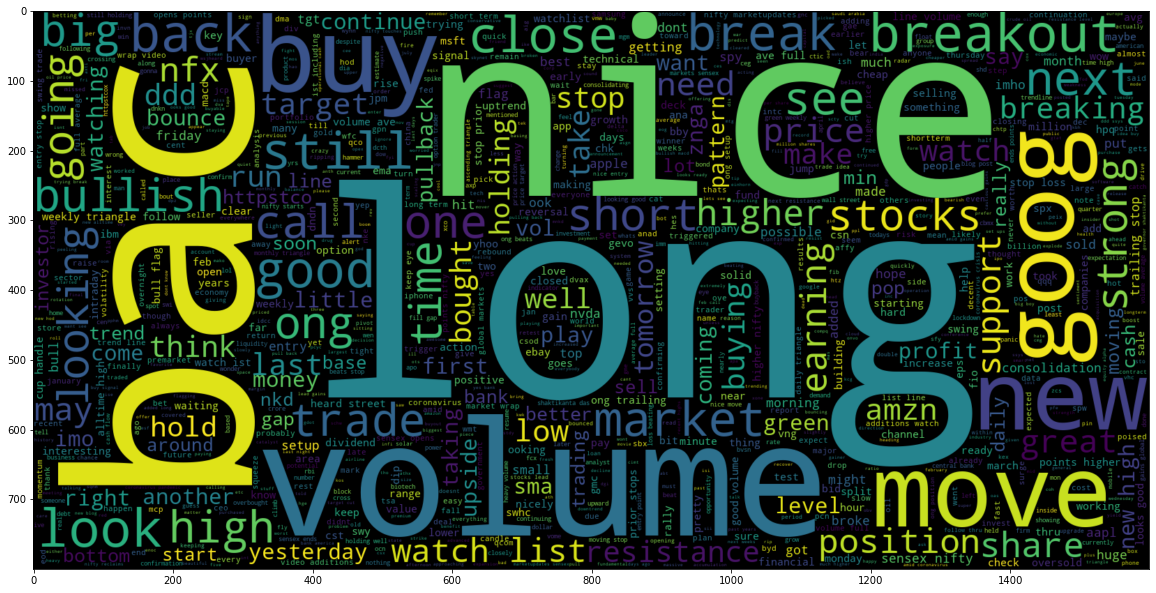
Figure 1 : Common Positive Words
In the above, wordcloud plot we can see the words which have positive sentiment or which indicates that the stock may move up.
# Most common words used in Negative Sentiment
plt.figure(figsize = (20,20))
wc1 = WordCloud(max_words = 1000 , width = 1600 , height = 800).generate(" ".join(stock[stock['Sentiment'] == 0]['Text Without Punc & Stopwords Joined']))
plt.imshow(wc1, interpolation = 'bilinear');
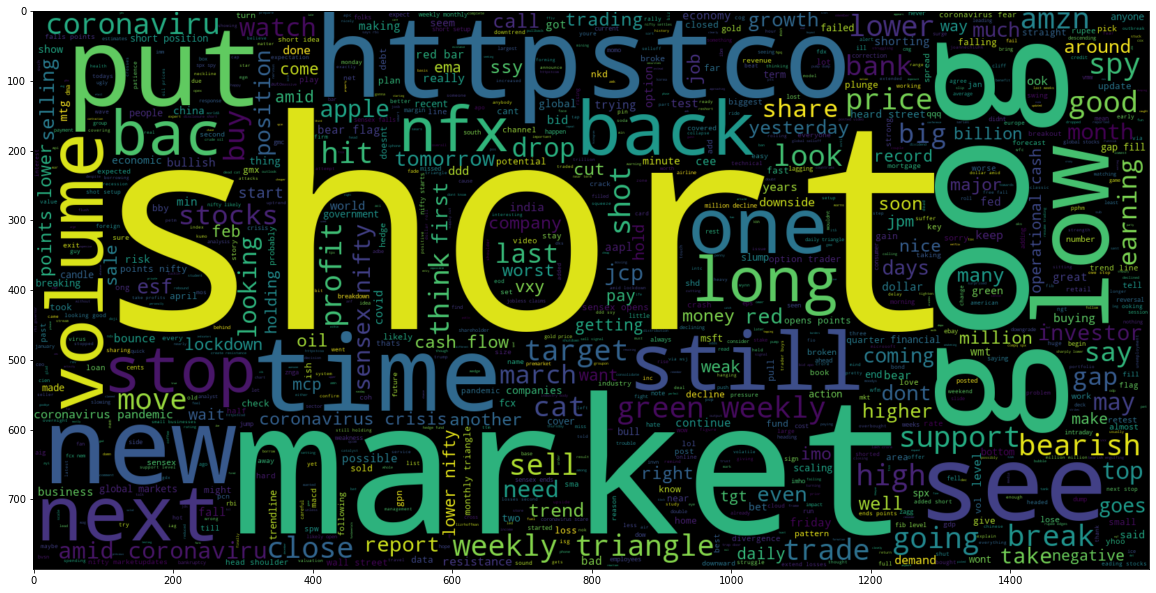
Figure 2 : Common Negative Words
In this wordcloud plot, we can see words which have negative sentiment or which indicates that the stock may move down.
Visualizing Cleaned dataset
In this part we will see the frequency of words and length of each tweet and assign them a numerical value for each word.
nltk.download('punkt')
# word_tokenize is used to break up a string into words
print(stock['Text Without Punc & Stopwords Joined'][0])
kickers watchlist xide tit soq pnk cpw bpz trade method method see prev posts
print(nltk.word_tokenize(stock['Text Without Punc & Stopwords Joined'][0]))
['kickers', 'watchlist', 'xide', 'tit', 'soq', 'pnk', 'cpw', 'bpz', 'trade', 'method', 'method', 'see', 'prev', 'posts']
# Obtain the maximum length of data in the document # This will be later used when word embeddings are generated maxlen = -1 for doc in stock['Text Without Punc & Stopwords Joined']: tokens = nltk.word_tokenize(doc) if(maxlen < len(tokens)): maxlen = len(tokens) print("The maximum number of words in any document is:", maxlen) The maximum number of words in any document is: 20 tweets_length = [ len(nltk.word_tokenize(x)) for x in stock['Text Without Punc & Stopwords Joined'] ] # Plot the distribution for the number of words in a text fig = plt.hist(x = tweets_length, bins=100) fig.show()
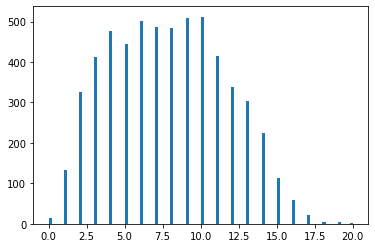
Figure 3 : Plot the distribution for the number of words in a text
# PREPARE THE DATA BY TOKENIZING AND PADDING
# Obtain the total words present in the dataset
list_of_words = []
for i in stock['Text Without Punc & Stopwords']:
for j in i:
list_of_words.append(j)
list_of_words[0:5]
['kickers', 'watchlist', 'xide', 'tit', 'soq']
list_of_words[45095:45098]
['factors', 'driving', 'dstreet']
# Obtain the total number of unique words
total_words = len(list(set(list_of_words)))
total_words
9268
Now we will split the data before assigning each word a particular number.
# split the data into test and train X = stock['Text Without Punc & Stopwords'] y = stock['Sentiment'] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1) X_train.shape (5211,) X_test.shape (580,) y.value_counts() 1 3685 0 2106 Name: Sentiment, dtype: int64
Process of assigning a number to text or word is known as tokenizing.
# Create a tokenizer to tokenize the words and create sequences of tokenized words
tokenizers = Tokenizer(num_words = total_words)
tokenizers.fit_on_texts(X_train)
# Training data
train_seq = tokenizers.texts_to_sequences(X_train)
# Testing data
test_seq = tokenizers.texts_to_sequences(X_test)
train_seq[0:2]
[[1289, 37, 91], [1884, 1, 39, 30, 3, 3616, 3617]]
print("The encoding for document\n", X_train[1:2],"\n is: ", train_seq[1])
The encoding for document
2 [afraid, short, amzn, looking, like, nearmonop...
Name: Text Without Punc & Stopwords, dtype: object
is: [1884, 1, 39, 30, 3, 3616, 3617]
# Add padding to training and testing padded_train = pad_sequences(train_seq, maxlen = 29) padded_test = pad_sequences(test_seq, maxlen = 29) for i, doc in enumerate(padded_train[:3]): print("The padded encoding for document:", i+1," is:", doc) The padded encoding for document: 1 is: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1289 37 91] The padded encoding for document: 2 is: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1884 1 39 30 3 3616 3617] The padded encoding for document: 3 is: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 64 84 485 173 3618 985 1115 1885 1290 155 1886 1291 1887 15 3619 7]
# Convert the data to categorical 2D representation y_train_cat = to_categorical(y_train,2) y_test_cat = to_categorical(y_test,2)
Building LSTM model
# Sequential Model
model = Sequential()
# embedding layer
model.add(Embedding(total_words, output_dim = 512))
# Bi-Directional RNN and LSTM
model.add(LSTM(256))
# Dense layers
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.3))
model.add(Dense(2,activation = 'softmax'))
model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['acc'])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 512) 4745216
_________________________________________________________________
lstm (LSTM) (None, 256) 787456
_________________________________________________________________
dense (Dense) (None, 128) 32896
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 2) 258
=================================================================
Total params: 5,565,826
Trainable params: 5,565,826
Non-trainable params: 0
_________________________________________________________________
# train the model model.fit(padded_train, y_train_cat, batch_size = 32, validation_split = 0.2, epochs = 3) Epoch 1/3 131/131 [==============================] - 37s 237ms/step - loss: 0.6101 - acc: 0.6570 - val_loss: 0.5213 - val_acc: 0.7411 Epoch 2/3 131/131 [==============================] - 31s 236ms/step - loss: 0.2690 - acc: 0.9030 - val_loss: 0.5403 - val_acc: 0.7488 Epoch 3/3 131/131 [==============================] - 30s 230ms/step - loss: 0.1174 - acc: 0.9605 - val_loss: 0.7665 - val_acc: 0.7440
# make prediction pred = model.predict(padded_test) # make prediction prediction = [] for i in pred: prediction.append(np.argmax(i)) # list containing original values original = [] for i in y_test_cat: original.append(np.argmax(i)) # acuracy score on text data from sklearn.metrics import accuracy_score accuracy = accuracy_score(original, prediction) accuracy 0.7603448275862069
# Plot the confusion matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(original, prediction) sns.heatmap(cm, annot = True)
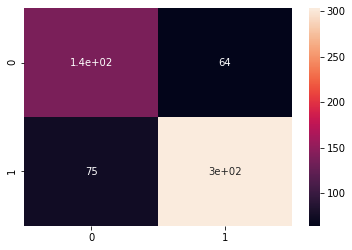
Figure 4 : Plot of Confusion Matrix in Stock News Analysis
Conclusion
We got the accuracy of approx. 76% using LSTM model we can further increase the accuracy by finding the best hyper parameter for this model and this can be done by hyper parameter tuning, you can read more about this from here.
Other methods can also be used to increase the accuracy of the model. You can read the article on How to perform Sentiment Analysis in python.
About the Author's:
Write A Public Review